
티스토리 뷰
머신러닝으로 문제를 해결한다는 것은 데이터에 맞는 모델, 적합한 손실함수, 최적화 방법, 평가 방법을 찾는 과정이다.
8.1 모델 문제
모델 자체에서 비롯된 문제를 해결해서 모델의 성능을 향상하는 방법을 크게 둘로 나눠 설명한다. 첫 번째는 학습할 때는 잘 동작했는데 실제로 사용하니 성능이 생각보다 잘 나오지 않는 과학습(오버피팅, 과적합, 과적응) 문제를 해결하는 방안을 알아보고, 두 번째는 데이터에 적합한 모델을 효과적으로 찾는 방법에 대해 알아보자.
1) 과학습
머신러닝 시스템을 기존 데이터로 학습시킨 후 평가했을 때는 좋은 성능이 나와 학습이 잘 되었다고 판단했는데, 새로운 데이터에서는 예상대로 성능이 나오지 않는 경우의 원인은 대부분 과학습 때문이다. 과학습은 말그대로 모델이 과하게 학습 데이터에 집중한 나머지 필요 이상으로 패턴을 학습한 경우이다.
그렇다면 이 문제를 어떻게 해결해야 할까? 그리고 이런 현상이 일어날지 어떻게 미리 알 수 있을까? 이제부터 과학습을 해결하는 실용적인 방법을 알아보자.
** 학습-평가 데이터 나누기
과학습 문제를 발견하는 가장 효과적인 방법은 전체 데이터의 일부만으로 모델을 학습시키고 나머지 데이터를 이용해 모델을 평가해서 얼마나 데이터의 일반적인 패턴을 잘 학습하는지 판단하는 것이다. 일반적인 패턴을 잘 파악하지 못하는 모델은 그렇지 않은 모델에 비해 학습용 데이터에서는 좋은 성능을 보이지만, 평가용 데이터에서는 성능이 잘 나오지 않는 현상을 보이게 된다.
** 정규화
모델의 정규화는 바로 이런 과학습 문제를 해결하기 위해 등장했다. 정규화는 데이터를 설명할 수 있는 가장 간단한 가정만을 사용한다는 '오컴의 면도날 가정'을 이용하여 과학습을 막는다. 데이터의 패턴을 복수의 가정으로 설명할 때는 데이터의 패턴에서 심하게 벗어나지 않으면 되도록 간단하게 가정을 사용하는 것이 좋다.
'데이터의 패턴에서 너무 벗어나지 않는 것'과 '더 간단한 모델을 사용하는 것'의 균형은 정규화 파라미터로 결정한다. 그렇다면 그 파라미터를 어떻게 결정해야 할까? 정규화 파라미터를 결정하는 데이터셋을 따로 빼놓고 학습하는 방법을 많이 사용한다.
정규화 파라미터가 실제로 어떤 영향을 미치는지 간단한 예제를 통해 알아보자. 사이킷런의 linear_model.Ridge 클래스는 정규화 파라미터를 지원하는 선형 회귀 클래스이다.
class sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True, normalize=False, copy_X=True, max_iter=None, tol=0.001, solver='auto', random_state=None)
여기서 정규화와 관련된 파라미터는 alpha인데, 값이 클수록 정규화의 강도가 더욱 강해진다.
실제로 어떤 문제가 발생하는지 시각적으로 보기 위해 2차 함수를 따르는 데이터를 만든 후 10차 함수 형태의 모델을 사용하는 경우를 알아보자(현실에서는 데이터가 몇 차원 함수를 따르는지 알 수 없으므로 임의로 높은 차원을 가정).
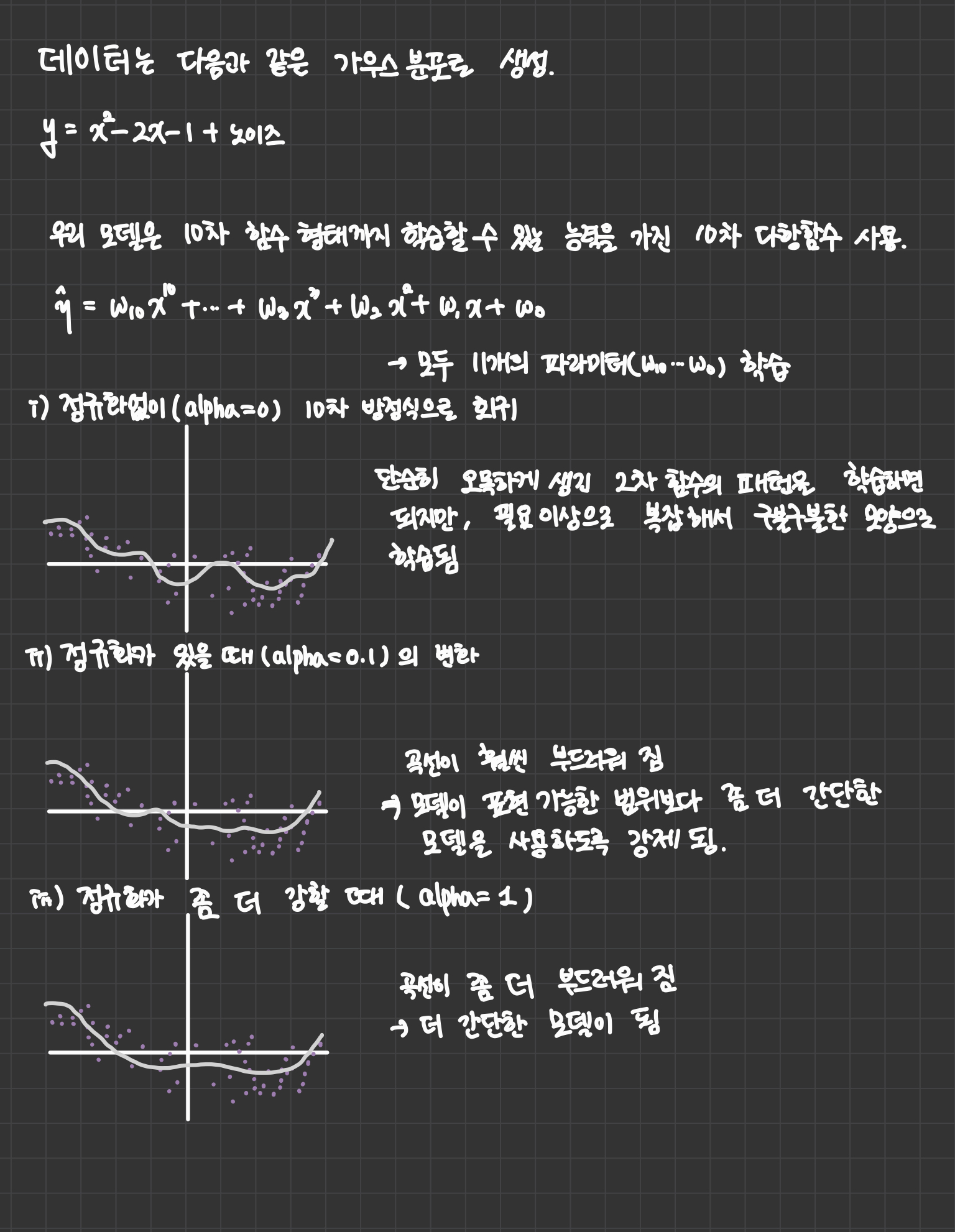
이렇게 정규화 파라미터를 조절하면서 필요 이상으로 복잡한 패턴을 학습하지 않도록 머신러닝 모델을 조절할 수 있다. 그렇다면 적절한 파라미터 값은 어떻게 찾을 수 있을까?
* 검증용 데이터를 나누어 정규화 파라미터 정하기

1. 데이터를 학습 및 검증용(A)과 테스트용(B)으로 나눈다.
2. A를 다시 학습용(C)과 검증용(V)로 나눈다.
3. 학습용 데이터에 대해 적당한 정규화 파라미터로 학습을 수행한 후 검증용 데이터를 사용해 성능을 측정한다. 반복해서 V에서 가장 성능이 좋은 정규화 파라미터를 찾는다.
4. 과정 3에서 찾은 정규화 파라미터를 이용해서 A에 대해 학습을 수행한다.
5. 모델 자체에 대한 평가는 B로 하면 된다.
** 학습을 일찍 끝내기
'Study > 처음 배우는 머신러닝' 카테고리의 다른 글
| [ Part Ⅱ] Chapter 7. 이미지 인식 시스템 만들기 (0) | 2021.07.28 |
|---|---|
| [ Part Ⅱ] Chapter 6. 영화 추천 시스템 만들기 (0) | 2021.07.25 |
| [ Part Ⅱ] Chapter 5. 문서 분석 시스템 만들기 (0) | 2021.07.15 |
| [ Part Ⅱ] Chapter 4. 구매 이력 데이터를 이용한 사용자 그룹 만들기 (0) | 2021.07.11 |
| [ Part Ⅱ] Chapter 3. 데이터와 문제 (0) | 2021.07.08 |
- Total
- Today
- Yesterday
- 러스트
- 17478
- 2805
- 프로그래머스
- 1182
- 파이썬
- 빌림
- 큐
- 딕셔너리
- 백준
- dp
- 백트래킹
- 1759
- 11051
- 자료구조
- 10845
- 10971
- 싸피
- 1715
- heapq
- 수학
- 1358
- 스택
- 1764
- 10815
- 브루트포스
- 삼성청년소프트웨어아카데미
- 10816
- 덱
- 조합
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |